


At the simplest level, search is the process of finding matches to a user-provided query string. While this base-level version of search is sometimes still utilized in simpler applications, for the most part, the results from queries that users perform are personalized to them, in order to surface documents that are more likely to be relevant to the user’s interests. In this post, we’ll discuss how companies are personalizing their search functionality, and the challenges they face when doing so, as well as touch on how personalized †search differs from personalization and recommendation engines in general.
What is Personalized Search?
As alluded to above, personalized search is the process of finding relevant documents given a (). Sometimes, the “user” portion of the query only pertains to what the user has previously searched for within the platform where they are performing the search. Other times, additional context, like the user’s profession, browser history, or user’s location, comes into play. Without the search, itself, being personalized, users can still add additional context to their input, such as adding “near me” to a query for “restaurants”, but many companies are removing the need for the user to provide such explicit queries, delighting consumers as the platforms seem to “read their minds”.
Primer on Information Retrieval
Information retrieval for personalized search typically involves using a combination of machine learning algorithms and vector space models to rank and retrieve search results that are relevant to the user's interests and preferences.
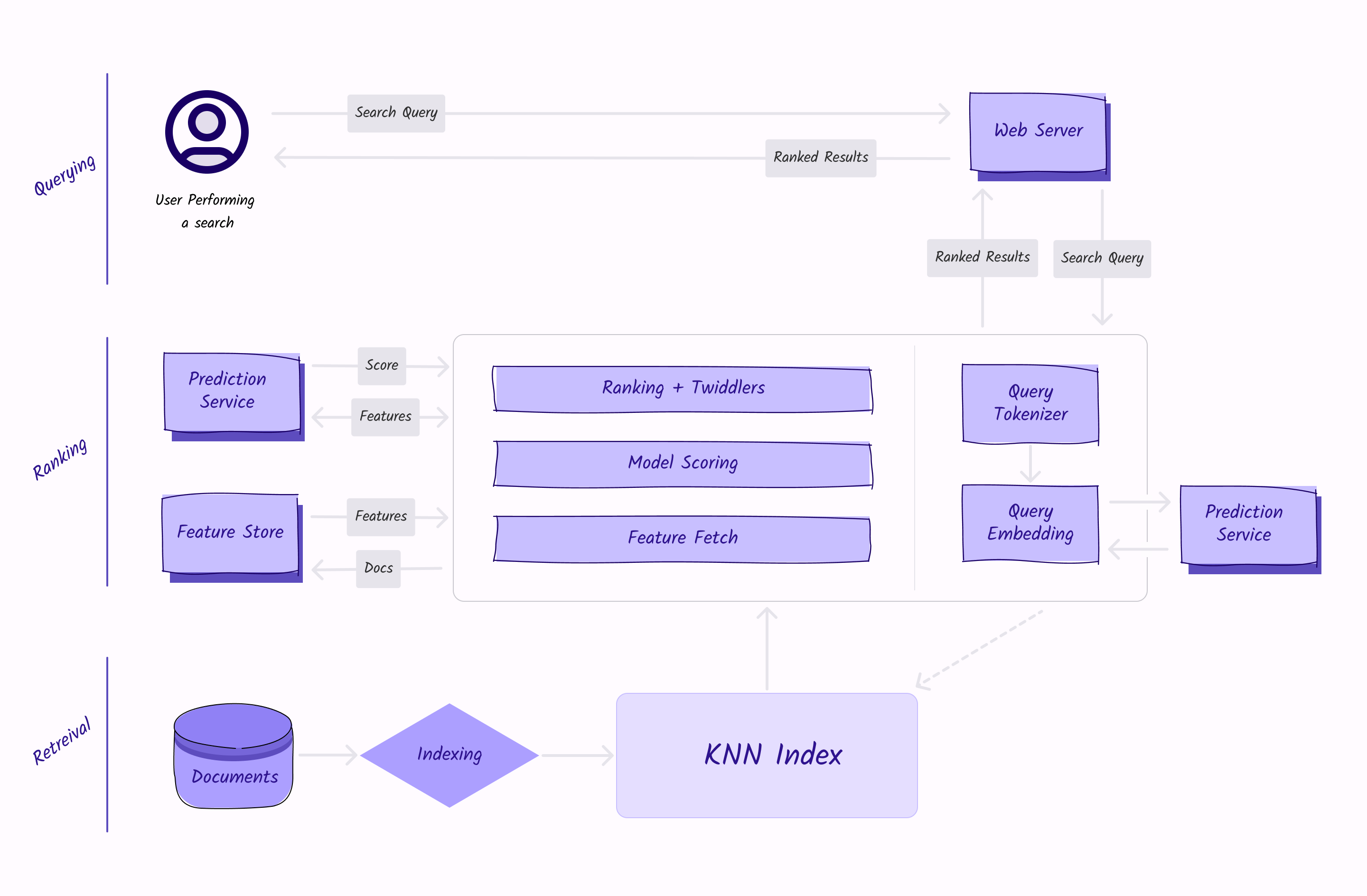
Traditional Information Retrieval Approach
Search engines have typically relied on a reverse index-based information retrieval system, which maps individual words or terms in the documents or records, and helps drastically reduce the candidate sets by several orders of magnitude. One popular example of this is Elasticsearch, which is built on Apache Lucene, a text search engine library. Elasticsearch stores data in an index and searches the inverted indices for query terms when a query is submitted. When a match for the query term is found, the corresponding document is returned. Breaking down the documents and identifying them by their key terms allows for faster retrieval of results.
With that being said, it is becoming more popular to use semantic retrieval, which uses semantic knowledge like natural language processing, to improve search results by utilizing the meanings of words or phrases in the context of a query, rather than just looking for an exact query term. A reverse index can still help with basic full-text search use cases, but a semantic retrieval system is more sophisticated and often provides more relevant and accurate search results in a wider variety of use cases.
Semantic Retrieval
While there are many ways to perform semantic retrieval, TTSN with BERT is frequently used in combination with KNN indices when working with personalized search.
TTSN with BERT
A two-tower sparse network (TTSN) is a type of machine learning algorithm that is designed to learn from high-dimensional, sparse data. It is composed of two separate neural networks, or "towers," and for personalized search, usually, one tower will handle the query aspect, and the other handles the retrieved documents. The TTSN as a whole is used to model the user’s interests and preferences, based on the user’s search queries and the search results that the user has clicked on in the past, as well as features such as the user’s location and time of the search.
In both towers, BERT (Bidirectional Encoder Representations from Transformers) can be utilized to perform natural language processing. BERT uses deep learning to understand and generate natural language text, which can help with analyzing and understanding the user’s search queries to determine the user’s intents, and can also help with analyzing the contents of the documents returned, allowing the system to rank and re-order the search results, so that the most relevant results are presented to the user at the top of the list.
KNN
A KNN index (k-Nearest Neighbor index) is a type of data structure that is used to efficiently search for the K nearest neighbors of a given point in a high-dimensional space. For personalized search, a KNN index is used to model the user's interests and preferences, based on the user's past search queries and the search results that the user has clicked on (which are modeled by the TTSN). When the user submits a new search query, the KNN index helps to quickly identify the search results that are most similar to the user's interests and preferences. This could involve calculating the similarity between the user's interests and preferences and the content of the search results, using a similarity measure such as cosine similarity. The search results could then be ranked and re-ordered based on their similarity to the user's interests and preferences.
Putting It All Together
Once the language model (BERT) has been used to process the context of the query and results, and the two-tower sparse network (TTSN) has been employed to learn from the query terms and their potential meanings, all of the documents can be embedded into a K-nearest neighbor (KNN) index. This index will embed the query at query time to find the nearest neighbors among the document vectors for a given query embedding, providing quick access to the most relevant documents for the query terms and the user performing the query.
Recommendation Engine vs. Personalized Search
Building a personalized search system is similar to building a recommendation system, where we recommend documents instead of items. With that being said, there are a few key differences between the two:
- Purpose – For search, there is often a “right” answer; the purpose is more “black and white”, since the user inputs a query for the information they are looking for, and the goal is to output the document with the information they are looking for. For a recommendation engine, there is generally more than one “right” product or song, etc., to recommend to the user, based on their previous engagements or purchases. Feature engineering for recommendations typically involves designing features that can capture a wide range of user interests and preferences, which can be used to make recommendations or personalized content in a variety of applications. In contrast, feature engineering for personalized search is more focused on designing features that can be used to rank and retrieve search results (documents) that are relevant to the user.
- Candidate Set – Search typically has a much larger pool of candidates, since creating documents is cheap compared to creating an item that typically represents a physical resource such as a product or maybe a movie. Users are not frequently repeatedly looking for the same information; however, they are frequently purchasing or engaging with, at least, the same type of products or movies, etc. This means that search has a much more severe long tail than recommendations.
- Input – The input to a recommendation engine is typically a () with a lot of weight on the user, while for a search engine, it is typically () with much more weight on the query. In personalized search, the data typically consists of the user's search queries, the search results that were clicked on by the user, and other relevant information, such as the user's location and the time of the search. In contrast, recommendations often use a wider range of data, including user profiles, social media data, and other information that can help to better understand the user's interests, preferences, and habits.
In many cases, a combination of personalized search and a recommendation engine is required. For example, if the user is searching for a specific product on Amazon or looking for a particular artist on Spotify, the query is used to filter the candidate set and recommendation functions can be used to perform sorting, also show parallel results that may be of interest, etc.
Types of Features Used
Search engines need to have a balance of engagement-based features and content-based features. Engagement-based features optimize for which of the documents that most closely match the user’s query should be shown first. Content-based features cover the long tail that results from:
- Users infrequently searching for the same information once they’ve found it.
- Users often using different queries (synonyms, slightly different levels of detail, etc.) to search for the same information, whether it is different users searching for the same information, or the same user returning at a different time to find information they searched for in the past.
For personalized search, some of the most common kinds of features include:
- NLP-Type Features – Features that understand the semantic content of the query. These might come from SOTA models (such as BERT), FastText (either directly fed or the dot product of the query), or document embeddings.
- Simple Content-Based Features – Simple features that give “basic metrics” for the documents, like the character or word count, presence of stop words, the term frequency-inverse document frequency (TF-IDF) of the query terms in the document, etc.
- Counter-Based Engagement Features – User/documentation engagement features, such as number of clicks the document has received, number of long clicks the document has received (clicks which had a view time > x seconds), bounce rate, etc.
- Reputation Features – Features representing how reputable of a source the document comes from. These might include the author of the document, the number of inbound links, the page rank, etc.
- Context Features – Features representing the context for how or when the query happened, such as the time of day or day of the week when the query was performed, the user’s location and/or IP address, the device the query was made from, whether the query was made on mobile or web, etc.
Challenges in Feature Engineering for Search
Feature engineering for personalized search has some of the same challenges as recommendation engines, since some of the features utilized are context-based, but there are other challenges that are more specific to or prevalent in personalized search, like the long-tail issues referenced above. Other challenges that are common in feature engineering for personalized search include:
- Latency – Users have become accustomed to having quick access to information. Newly built search features need to accommodate this expectation, so latency is a big factor with search of any kind. This means that feature retrieval needs to be quick, in order to simultaneously meet this expectation and allow for the more time-intensive model scoring to take place. To optimize for low latency, ensure that your algorithms and indexing processes are optimized. You can also opt to upgrade your hardware, but optimization should be the first plan of attack for the most cost-efficient solution.
- Large number of candidates – As mentioned above, there is a much higher number of resources to sort through for search than for many other use cases of ML. A given query typically needs to score hundreds of candidate documents (or more), and the feature store needs to support high throughput. In order to optimize your system for search, it is pertinent to choose the correct features that will help you most quickly narrow down results; this can be done with proper feature selection algorithms or dimensionality reduction techniques and can be made easier by ensuring the freshness of features (as referenced below).
- Experimentation Velocity – Since a search system has several components (query, context, user, document, etc.), there are a large number of combinations that could be tried for potential features. To quickly find the best features and feature combinations, the system needs to be easy to experiment with and iterate on. Streamlining your system can be done by automating steps like data preparation and feature extraction, or leveraging the power of parallel computing to test more features in a shorter amount of time.
- Freshness – The candidate pool for a search system is very dynamic, and new documents are constantly being added; to accommodate this, features need to be updated quickly. Practices like time series analysis can help to identify trends in data over time and help you ensure you are staying on top of the most quickly changing features; it is also important to have monitoring in place (like with any realtime ML pipeline) to ensure features are not going stale.
- Multi Corpus – Search typically needs to deal simultaneously with multiple corpuses, such as Articles, News, Videos, Web pages, or different sources of documents, such as Notion, Google Docs, Slack, Coda, etc. In enterprise search, engineers need to be able to engineer features that cater to each domain and have them all seamlessly combine and integrate to provide the quickest and most relevant results. NLP can really come into play when working with a wide variety of sources, like feature engineering for search. Other methods that are useful are models that combine data from multiple sources, like support vector machines (SVMs) or random forest, and dimensionality reduction techniques, such as principal component analysis (PCA) or singular value decomposition (SVD).
Wrapping Up
Personalization is creeping its way into more and more applications of feature engineering, causing people to expect every system they interact with to feel intuitive, including search. There are some nuances with how personalization applies to search, making it both easier and harder to engineer than functions like recommendation engines, because of the lesser degree to which personalization comes into play, but also the number of documents to be found and prioritized, and the speed at which this all needs to happen. The challenges to be solved for will vary slightly based on the use case of the search function being engineered, but many have been presented here, with solutions for how to engineer for them in the first place to help you start off the feature engineering for your search function with the highest level of success.
Originally published at https://fennel.ai on December 20, 2022.